
Repositories across the globe are leveraging the open source power of Dataverse to publish, share and archive research data. The Dataverse community led by IQSS at Harvard University is growing rapidly and a new Global Dataverse Community Consortium with members around the world is forming. One of the most powerful features of Dataverse is its ability to index quantitative data to make it discoverable. Automated tools launched during the ingest of these file types create variable level metadata that is stored and indexed by the system. Users enjoy the ability of searching vast amount of data with granular variable level queries. For published non-sensitive public data that is also not excessive in size this works great.
When selecting a central indexing platform for the ImPACT project Dataverse was a perfect fit but the ability to describe and document the variable level details required Dataverse to transfer the file and have the ability at the server to process the information. When data is either sensitive and controlled by restrictive data use agreements or is too large to easily move the ingest process of Dataverse falls short. The ImPACT team is working to design and develop a Trusted Remote Storage Agent (TRSA) that can solve this problem and allow the pre-processing of data at the client’s side and publish the metadata within Dataverse for discovery while the sensitive or large data remains in the secure remote storage location.
The design of the ImPACT Data Ingest workflow places the TRSA locally in the data providers (DP) environment and all processing takes place locally before the metadata is pushed to Dataverse using the Dataverse API. http://guides.dataverse.org/en/latest/api/index.html
Data never leaves the confines of the DP storage infrastructure for processing. The metadata collection is done locally to DP infrastructure by the code trusted to perform only certain actions on the datasets and not to disclose any metadata the DP is not willing to share
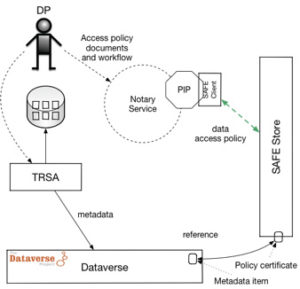
To ensure the discoverability and integrity of the data indexed by these systems, DPs will be required to develop or utilize existing Memorandums of Understanding (MOU’s) with archives hosting the Dataverse instances. Since the network of Dataverses will be linked by harvest mechanisms that allow discovery of content anywhere in the system, DPs can select any number of Dataverse instances to collaborate with or run their own when required. These MOU’s will serve as the binder that allows a DP to become a Remote Trusted Storage Agent and ensure the integrity of the archival collection. Part of the MOU will require the DP to ensure that updates to the collection are noted in the Dataverse system collaborating. This will prevent invalid or broken links from persisting in the system.
The architectural design of the ImPACT TRSA is based on a light weight approach that records submissions locally in text format and utilizes Dataverse API calls to track progress of submissions. The abstraction of the Dataverse ingest tools to run at a remote site will allow secure systems to register restricted data with Dataverse and acquire a Digital Object Identifier (DOI) for the publication of the data as well as publishing metadata at the variable level when security policies allow. By leveraging the public Dataverse APIs to publish metadata the tool will be scalable and sustainable for many organizations. The TRSA also has application for data repositories that house very large data that are impractical to move while still allowing the indexing of detailed metadata.
Project-wise, TRSA is one of the long-term collaborative efforts between IQSS and Odum Institute because implementing TRSA entails significant changes to Dataverse in terms of its API and package structure. As mentioned above, the publishing feature of TRSA needs the new API endpoints of Dataverse so that Dataverse can accept a metadata-only-publishing request from TRSA. Also, if TRSA is indispensable to the ecosystem of Dataverse in the long run, its source-tree must be synced with the counterpart of Dataverse because TRSA adapts a few components of Dataverse. And this shared code naturally, for the ease of maintenance and avoidance of duplicated efforts, leads to a solution that turns these shared source files into a stand-alone, publicly shareable package; ingest-related source files fall under this category and independent ingest package would also promote beneficial side-effects; for example, because even non-Dataverse projects can utilize the ingest package, more external coding contributions/enhancements to the package could be expected, which has been very difficult for the current tightly intertwined, monolithic code-base of Dataverse.