
Welcome to the ImPACT Blog! In this blog the members of this National Science Foundation-funded project will share their insights on how to construct and operate infrastructure solutions that support collaborative analysis on restricted data. ImPACT stands for Infrastructure for Privacy-Assured CompuTations. The project team brings together RENCI and Odum institutes from UNC Chapel Hill, SSRI (Social Science Research Institute) and OIT (Office of Information Technology) from Duke University, Indiana University Cybersecurity Center of Excellence and Dataworks – a Durham, NC non-profit dedicated to democratizing the use of quantitative information.
Why the data is restricted could be for a multitude of reasons, most often – due to the presence of PII (Personally Identifiable Information), but there can also be commercial competition concerns. The types of data and collaborative scenarios covered by the project are quite broad, however we are currently focusing on supporting social science research, as it presents the most challenging set of problems and those problems, if solved, provide the opportunity for most societal (you guessed it) impact. By working with social scientists at Odum, SSRI and NIEHS we have identified a number of distinct use-case collaborative scenarios that are driving the technical project towards implementing the solutions. We will be delving into the details of these use-cases in this blog.
We are also implementing an architecture that can support these and other use cases in the future. Elements of the architecture will be described in this blog, but briefly, it consists of the following pieces:
- Technologies to enable the discovery of restricted data without exposing the data itself
- Technologies to help automatically negotiate Data Use Agreement policies between multiple parties, automatically linking the execution of the agreements to data access control decisions
- Technologies to build and operate isolated enclaves deployed across institutions, where restricted data can be analyzed in a collaborative setting, without exposing to the outside world
- Access policy control mechanisms that protect access to the restricted data residing with multiple independent data providers
- Technologies to enable collaborative analysis under the most restrictive conditions when data providers are completely unwilling to release the data to anyone else.
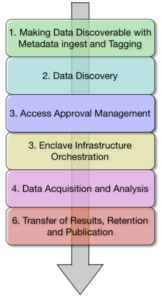
Looking at the figure below, we are focusing on each of the steps in the collaborative research workflow shown in it. Critically, while we are designing the various elements to work together, we are also highly cognizant of the fact that adopting new solutions is hard, as is getting the community mindshare. For this reason, most solution components can be used standalone to reduce the friction in the discovery process and simplify the research, however when used together they provide the most benefit to the research community – all of this will be described in this blog.
Stay tuned for more, as we explore the different parts of this exciting and important problem space!